


Ready to build better conversations?
Simple to set up. Easy to use. Powerful integrations.
Get free accessReady to build better conversations?
Simple to set up. Easy to use. Powerful integrations.
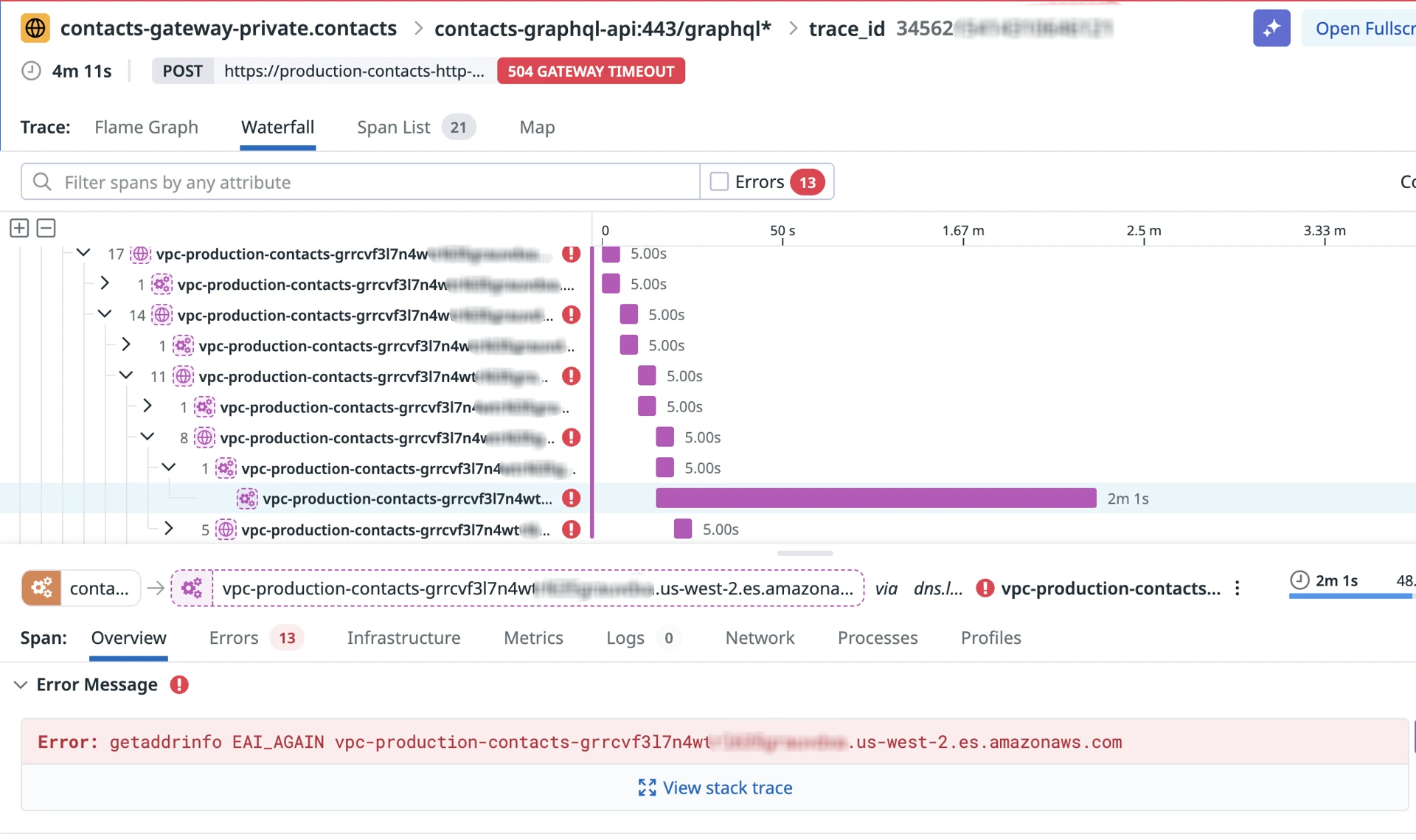
Get free accessHow a single dig +tcp command finally revealed why one of our OpenSearch clusters was unreachable from half our Kubernetes pods, and why it stopped a production migration in its tracks.
The symptom
It started during an ongoing production migration. We were moving one of our backend services from ECS to EKS, a routine but careful operation. Partway through, the service running on EKS started failing to reach its OpenSearch cluster. Application logs filled with timeouts on what should have been simple HTTP calls. We paused the migration, kept the ECS workload serving traffic, and started investigating.
Nothing about the setup looked unusual. The service runs on EKS. The OpenSearch domain runs in the same VPC. We had been operating both for months without incident. And critically: a different OpenSearch domain, used by the same pods in the same namespace, worked perfectly fine.
That last detail is what made the problem interesting. It was not a generic networking outage. Something about this specific OpenSearch cluster was unreachable, and only from inside our mesh. The migration could not move forward until we understood why.
First clues
We shelled into one of the failing pods and ran the most basic check possible. The application container was a slim Node.js image with no dig or nslookup installed, so we used getent hosts, which works against whatever resolver the system is configured with:
Empty output. The hostname was not resolving. Meanwhile, in the same pod:
Three IPs, returned instantly. So DNS worked, just not for one specific name.
Even stranger: the istio-proxy sidecar in the same pod could resolve the broken name fine. We ran the same getent command from the istio-proxy container and got back 32 IP addresses:
Same network namespace. Same /etc/resolv.conf. Different result.
That asymmetry was the loose thread we would spend the next several hours pulling on.
Hypothesis 1: AWS networking issue
Our first instinct was to suspect AWS networking. We compared production against staging, where the two environments are built from the same Terraform modules and the same OpenSearch domain class. In staging, OpenSearch was reachable from EKS without issue. In production, with what should have been an identical setup, it was not. That comparison made an AWS-side misconfiguration the natural first place to look.
We checked the usual suspects:
Security Group rules. Could a missing or misordered rule be blocking outbound DNS to the VPC resolver, or pod-to-OpenSearch traffic on the data path?
NACLs. Subnet-level network ACLs are stateless and a common source of "works here, not there" asymmetries.
Route tables. Could the broken cluster sit in a subnet with a route table that does not include the right path to the VPC resolver or to OpenSearch's ENIs?
Private hosted zones. OpenSearch VPC endpoints rely on a private hosted zone being associated with the VPC. If that association was missing or scoped differently in production, lookups would fail.
We went through all of them. Security groups allowed both UDP and TCP on port 53 to the VPC resolver and to OpenSearch. NACLs were permissive in both directions. Route tables matched staging. The private hosted zone for OpenSearch was correctly associated with the production VPC.
Nothing on the AWS side looked wrong. And the staging-vs-production comparison ruled out anything environmental at the infrastructure-as-code level: whatever was different had to live above AWS, somewhere in the cluster itself.
Hypothesis 2: CoreDNS forward configuration
If AWS was clean, the next likely culprit was CoreDNS itself. The forward plugin in CoreDNS sends queries it cannot resolve locally to an upstream resolver, typically /etc/resolv.conf on the node, which on EKS points at the VPC resolver 10.0.0.2. A misconfiguration there would not stop DNS from working entirely, but it could absolutely break specific zones if AWS-internal queries were being sent to the wrong upstream.
We pulled the production Corefile:
Standard EKS defaults. forward . /etc/resolv.conf forwards everything not handled locally to whatever the node's resolver is, which is the VPC resolver. No custom zone overrides, no alternate upstreams, no split-horizon trickery. We compared it to staging line by line. They were identical.
So CoreDNS was not selectively misforwarding queries either. And we already had a clue that CoreDNS was answering these queries in some form: the istio-proxy container in the same pod was getting back all 32 OpenSearch IPs. CoreDNS knew the answer. Something between CoreDNS and the application container was eating it.
Hypothesis 3: DNS response size and UDP truncation
The next thing that jumped out was the size difference between the two OpenSearch domains. The working domain returned 3 records. The broken one returned 32. That is a meaningful jump in DNS payload size, easily over the classic 512-byte UDP limit.
A quick aside on that limit and what modern DNS does about it. The original DNS spec capped UDP responses at 512 bytes, which is small enough that any non-trivial response set needed TCP. EDNS0 (Extension Mechanisms for DNS, RFC 6891) was introduced to lift that ceiling: clients advertise a larger UDP buffer size (typically 1232, 4096, or higher) in their query, and servers that understand EDNS0 can send larger UDP responses without truncating. If the response still does not fit, the server falls back to setting the TC (truncated) flag and the client retries over TCP. Today, almost every resolver speaks EDNS0, but they vary in what buffer size they advertise, which matters in this story.
The textbook behavior here: when a DNS response exceeds the buffer the client advertised, the server sets the TC flag on the UDP reply, and a well-behaved resolver retries the query over TCP. We theorized that something in the path was preventing the TCP retry. Perhaps a NetworkPolicy that allowed UDP/53 but not TCP/53 to CoreDNS.
It was a clean theory. It explained the asymmetry: small response works over UDP, large response needs TCP, TCP is broken. It just turned out to be only half right, and we would not understand the other half for a while.
The breakthrough: a packet that should have worked
By this point we needed proper DNS tooling, and the application container did not have it. We attached an ephemeral debug container to the failing pod with kubectl debug, sharing the pod's network namespace so we would be testing the exact same resolver path the application sees, this time with dig available. From there:
UDP through CoreDNS: works. Returns the cached answer in 0 ms.
TCP to the same server: instant connection reset. Not a timeout, an active RST.
We ran the same TCP test against aircall.io to see if it was domain-specific:
Same result. Any TCP DNS query to CoreDNS got an immediate reset. The problem was not about the OpenSearch domain at all. TCP DNS through CoreDNS was completely broken from inside istio-injected pods.
To rule out CoreDNS itself, we ran the same query from a non-istio-injected pod:
Worked perfectly. Sub-10ms response.
So CoreDNS spoke TCP just fine. Security groups were fine. Network was fine. Envoy was the broken link.
Inside the Envoy listener
We pulled the listener config for kube-dns:
The listener was a normal TCP proxy pointing at the kube-dns cluster. Nothing exotic. All endpoints were marked healthy. No filter weirdness.
We looked at PeerAuthentication next:
Mesh-wide STRICT mTLS. This requires inbound connections to mesh-injected workloads to be mTLS. CoreDNS is not in the mesh, so PeerAuthentication does not directly apply to it, but it is a hint that we run a security-strict mesh.
Then DestinationRules:
There it was.
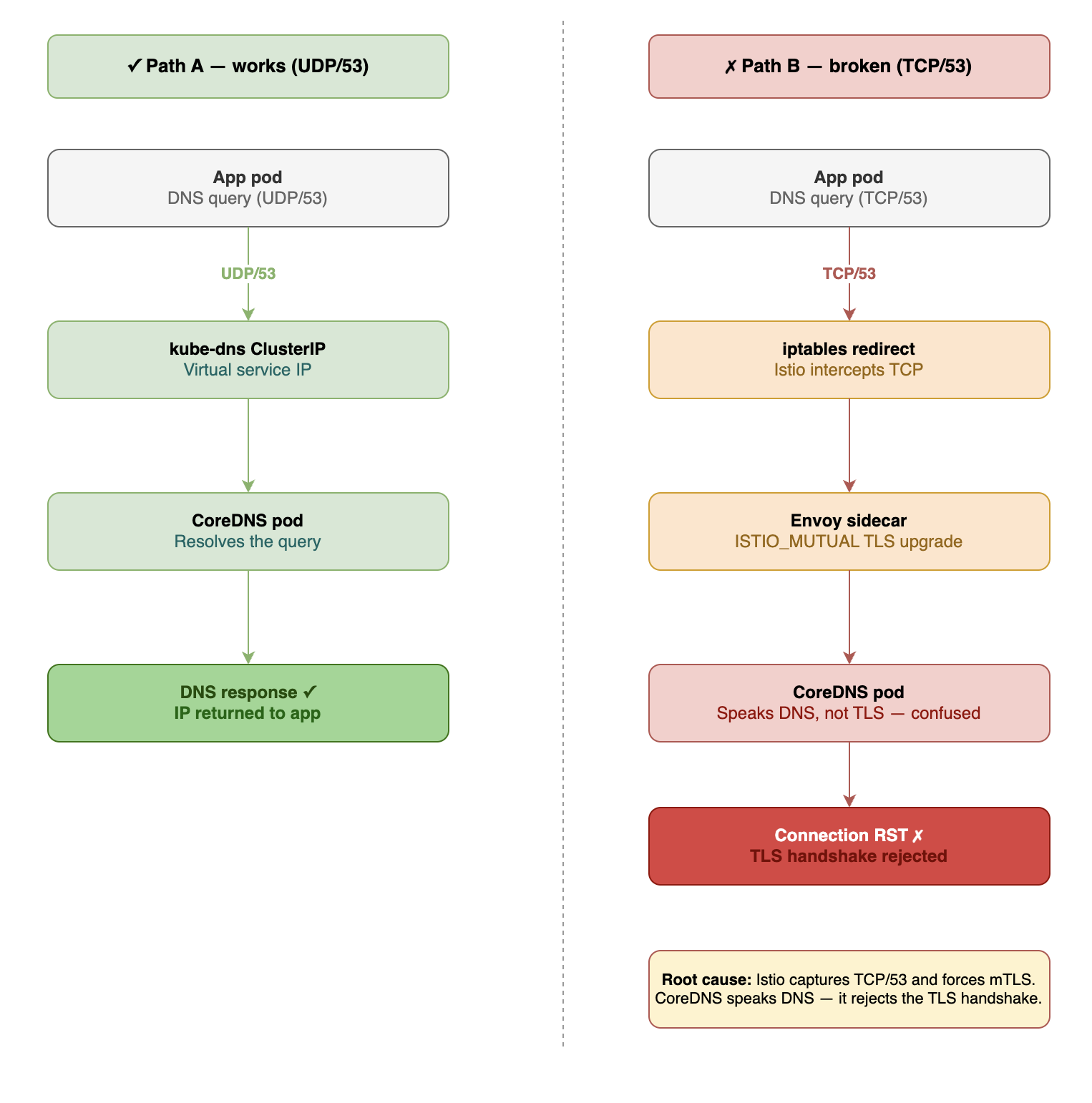
The actual cause
This DestinationRule, written to enforce mTLS for in-mesh service-to-service traffic, matched any host ending in .local. That includes kube-dns.kube-system.svc.cluster.local.
When our app's Envoy received an outbound TCP connection to the kube-dns ClusterIP, it consulted its DestinationRule config and saw: "for *.local, use ISTIO_MUTUAL." So it dutifully started a TLS handshake with CoreDNS, sending a TLS ClientHello.
CoreDNS, expecting a DNS message in TCP framing, received bytes that looked like complete garbage. It closed the connection. Envoy interpreted that as a transport failure and reset the connection back to our app.
Our app got connection reset. The request died. The OpenSearch lookup failed.
This explained every observation:
UDP works because Istio's iptables rules only redirect TCP traffic to Envoy. UDP packets, including DNS queries, take the default kernel path straight to CoreDNS via kube-proxy. Envoy never sees them, so the DestinationRule is never consulted and no TLS upgrade is attempted. (Envoy itself can proxy UDP, and Istio has an opt-in DNS proxy feature that intercepts UDP/53, but neither is on by default and we do not enable them. So in practice UDP bypasses the mesh entirely.)
The non-istio-injected pod works because there is no Envoy doing TLS upgrade.
The smaller OpenSearch domain works because its 3-record response fits in a single UDP packet. TCP fallback is never triggered.
The larger OpenSearch domain fails because its 32-record response is large enough that some resolvers (like Node.js c-ares with its smaller default EDNS0 buffer) request a TCP retry.
The istio-proxy container resolves it fine because traffic from UID 1337 is exempt from istio's iptables rules. The sidecar talks directly to CoreDNS without going through itself.
This bug had been silently broken in our cluster for years. Most workloads never noticed because most DNS responses are small enough to live entirely in UDP. The OpenSearch cluster scaled up at some point past the threshold, and the migration of this particular service exposed the issue at the worst possible moment.
The fix
A more-specific DestinationRule that overrides the *.local rule for kube-dns:
More-specific host matches take precedence. Envoy now proxies DNS over plain TCP for kube-dns while continuing to enforce mTLS for all other in-mesh traffic.
After applying it:
Resolution recovered immediately. The migration resumed the same day.
What we learned
A few things stayed with us after the fact.
Bugs hide behind thresholds. This one was sitting in our cluster the whole time, gated by a DNS response size. Any workload doing TCP DNS through Envoy was broken, we just had not had a workload doing TCP DNS through Envoy yet. As your infrastructure grows, you cross thresholds you did not know existed. Worse, you can cross them mid-migration, when you have the least slack to absorb a surprise.
Asymmetric symptoms are gifts. The fact that one OpenSearch domain failed and another succeeded was the entire investigation. Without that contrast, we would have looked at much higher-level causes (network outage, OpenSearch issue, security group). It is worth seeking out and characterizing asymmetries early. They collapse the search space dramatically.
Layered systems compound. The actual problem was small: one DestinationRule pattern that matched too broadly. But the symptoms surfaced through layers of abstraction (Node.js DNS resolution, libc, CoreDNS, istio-proxy, Envoy, DestinationRule, mTLS upgrade) that each had to be peeled back. Each layer gave us plausible-sounding theories that turned out to be wrong. The fix is one line; finding it took us through three wrong hypotheses first.
Wildcard rules are technical debt. host: '*.local' is a very tempting pattern. It "just works" for everything in the cluster, until something that is not meant to be in the mesh ends up matched by it. We have started auditing our wildcard rules and converting them to explicit lists where possible.
EDNS0, UDP buffers, and TCP fallback are still relevant in 2026. Most engineers think of DNS as "UDP, and TCP for zone transfers," but truncation and fallback happen routinely on production traffic and can be the silent canary for problems elsewhere.
The migration we paused has since completed successfully. The bug that almost derailed us is now a one-line DestinationRule we will not forget about.
If you’d like to hear more tips and stories from our team of innovators and developers, check out our full range of Tech Team Stories.
Published on June 2, 2026.
